1 PyTorch全局设置
1.1 全局设置当前设备
1.2 全局设置浮点精度
1.3 设置控制台输出格式
2 向量与梯度之核心
2.1 Tensor的组成与存储
2.2 Tensor的grad属性
2.3 Tensor内存布局的调整
2.4 Tensor的叠加
2.5 禁用梯度计算
2.6 向量的保存和加载
2.7 梯度消失与梯度爆炸
3 神经网络基础
3.1 线性网络的参数以及初始化
3.2 PyTorch计算图
3.3 查看网络权重参数
3.4 保存模型
3.5 Adam相关面试题
3.6 ReLu与非线性的理解
3.7 Train模式和Eval模式
3.8 线性网络
3.9 双线性网络
3.10 惰性线性层
3.11 参数向量
3.12 叶子节点
3.13 自动求导与链式求导
3.14 Dropout机制
3.15 detach原理
3.16 半精度训练
3.17 Xavier初始化
3.18 通道的深刻理解
3.19 1x1卷积的作用
3.20 注意力机制
3.21 requires_grad属性
3.22 向量的device
3.23 tensor与numpy互换
3.24 DataParallel用法详解
3.25 to(device)和.cuda()的区别
3.26 Dataset数据处理
3.27 StepLR学习率调度器
3.28 词嵌入的理解
3.29 特征提取和可视化
3.30 TensorDataset的使用
特征提取和可视化
创建时间:2024-09-17 | 更新时间:2024-09-17 | 阅读次数:1012 次
如果是自己构建的模型,那么可以再forward函数中,返回特定层的输出特征图。如果是预训练模型,建议使用create_feature_extractor获取指定层的输出的方法。
针对自己构建的模型
创建一个可以根据需要调用的特征提取器类,代码如下所示:
class Feature_extractor(nn.module):
def forward(self, input):
self.feature = input.clone()
return input
new_net = nn.Sequential().cuda() # the new network
target_layers = [conv_1, conv_2, conv_4] # layers you want to extract`
i = 1
for layer in list(cnn):
if isinstance(layer,nn.Conv2d):
name = "conv_"+str(i)
art_net.add_module(name,layer)
if name in target_layers:
new_net.add_module("extractor_"+str(i),Feature_extractor())
i+=1
if isinstance(layer,nn.ReLU):
name = "relu_"+str(i)
new_net.add_module(name,layer)
if isinstance(layer,nn.MaxPool2d):
name = "pool_"+str(i)
new_net.add_module(name,layer)
new_net.forward(your_image)
print (new_net.extractor_3.feature)
预训练模型
import torchvision
from PIL import Image
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
from torchvision.models.feature_extraction import create_feature_extractor
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,
0.456, 0.406], [0.229, 0.224, 0.225])])
model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
feature_extractor = create_feature_extractor(model, return_nodes={"conv1": "output"})
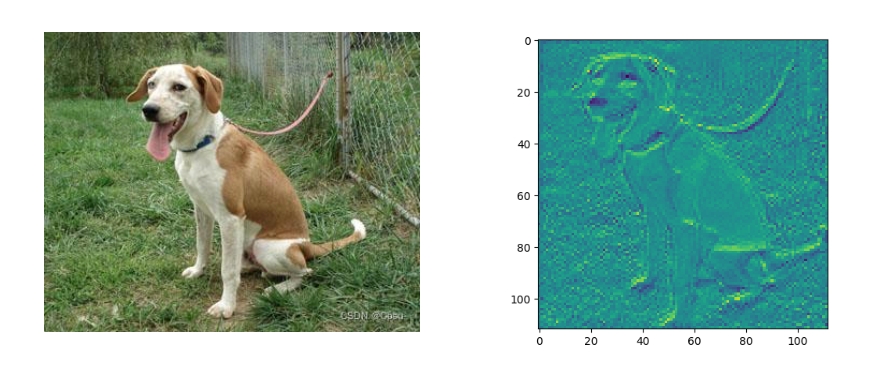
original_img = Image.open("dog.jpg")
img = transform(original_img).unsqueeze(0)
out = feature_extractor(img)
plt.imshow(out["output"][0].transpose(0, 1).sum(1).detach().numpy())
plt.show()
本教程共40节,当前为第39节!